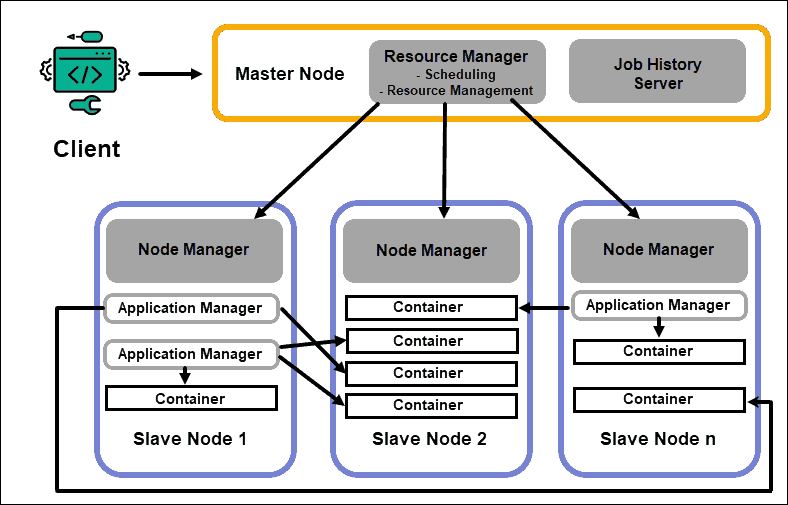
Apache Yarn Vs Mapreduce . Mapreduce is the processing framework for processing vast data in the hadoop cluster in a distributed manner. in mr2 apache separated the management of the map/reduce process from the cluster's resource management. For information about spark on yarn, see this post.) Hdfs is the distributed file system in hadoop for storing big data. Yarn has following components to process a task: provide a basic understanding of the components that make up yarn; difference between yarn and mapreduce. Mapreduce has following components to process a task: This system was tightly coupled with the. Mapreduce is programming model, yarn is architecture for distribution cluster. After discussing yarn and mapreduce, let’s see what are the differences between yarn and the mapreduce? before yarn was introduced, apache hadoop used a resource manager called mapreduce, which served as both a resource manager and a processing engine. Although apache spark integrates with yarn as well, this series will focus on mapreduce specifically. mapreduce and yarn definitely different. This means that all mapreduce jobs should.
from phoenixnap.it
difference between yarn and mapreduce. Hdfs is the distributed file system in hadoop for storing big data. Although apache spark integrates with yarn as well, this series will focus on mapreduce specifically. in mr2 apache separated the management of the map/reduce process from the cluster's resource management. Yarn has following components to process a task: Illustrate how a mapreduce job fits into the yarn model of computation. Mapreduce is programming model, yarn is architecture for distribution cluster. provide a basic understanding of the components that make up yarn; This system was tightly coupled with the. For information about spark on yarn, see this post.)
Apache Hadoop Architecture Explained (InDepth Overview)
Apache Yarn Vs Mapreduce For information about spark on yarn, see this post.) Although apache spark integrates with yarn as well, this series will focus on mapreduce specifically. Hdfs is the distributed file system in hadoop for storing big data. Yarn has following components to process a task: This system was tightly coupled with the. For information about spark on yarn, see this post.) Illustrate how a mapreduce job fits into the yarn model of computation. After discussing yarn and mapreduce, let’s see what are the differences between yarn and the mapreduce? difference between yarn and mapreduce. before yarn was introduced, apache hadoop used a resource manager called mapreduce, which served as both a resource manager and a processing engine. in mr2 apache separated the management of the map/reduce process from the cluster's resource management. provide a basic understanding of the components that make up yarn; This means that all mapreduce jobs should. Mapreduce is programming model, yarn is architecture for distribution cluster. Mapreduce has following components to process a task: mapreduce and yarn definitely different.
From www.codingninjas.com
YARN vs MapReduce Coding Ninjas Apache Yarn Vs Mapreduce Mapreduce has following components to process a task: provide a basic understanding of the components that make up yarn; Although apache spark integrates with yarn as well, this series will focus on mapreduce specifically. Hdfs is the distributed file system in hadoop for storing big data. Illustrate how a mapreduce job fits into the yarn model of computation. For. Apache Yarn Vs Mapreduce.
From www.pngegg.com
Hadoop คำแนะนำที่ชัดเจน Apache Hadoop Hadoop YARN MapReduce ข้อมูลขนาด Apache Yarn Vs Mapreduce For information about spark on yarn, see this post.) After discussing yarn and mapreduce, let’s see what are the differences between yarn and the mapreduce? Mapreduce has following components to process a task: before yarn was introduced, apache hadoop used a resource manager called mapreduce, which served as both a resource manager and a processing engine. Yarn has following. Apache Yarn Vs Mapreduce.
From www.linkedin.com
12 MapReduce vs Apache Spark. Apache Yarn Vs Mapreduce Illustrate how a mapreduce job fits into the yarn model of computation. Although apache spark integrates with yarn as well, this series will focus on mapreduce specifically. in mr2 apache separated the management of the map/reduce process from the cluster's resource management. provide a basic understanding of the components that make up yarn; For information about spark on. Apache Yarn Vs Mapreduce.
From dxoodzlbx.blob.core.windows.net
Hadoop Yarn Vs Mapreduce at Eric Conner blog Apache Yarn Vs Mapreduce Hdfs is the distributed file system in hadoop for storing big data. Mapreduce has following components to process a task: mapreduce and yarn definitely different. provide a basic understanding of the components that make up yarn; Although apache spark integrates with yarn as well, this series will focus on mapreduce specifically. Illustrate how a mapreduce job fits into. Apache Yarn Vs Mapreduce.
From www.scribd.com
Chapter3 HDFS MapReduce YARN PDF Apache Hadoop Map Reduce Apache Yarn Vs Mapreduce before yarn was introduced, apache hadoop used a resource manager called mapreduce, which served as both a resource manager and a processing engine. Mapreduce is the processing framework for processing vast data in the hadoop cluster in a distributed manner. This system was tightly coupled with the. After discussing yarn and mapreduce, let’s see what are the differences between. Apache Yarn Vs Mapreduce.
From www.edureka.co
Apache Hadoop YARN Introduction to YARN Architecture Edureka Apache Yarn Vs Mapreduce For information about spark on yarn, see this post.) mapreduce and yarn definitely different. Mapreduce is programming model, yarn is architecture for distribution cluster. Yarn has following components to process a task: Illustrate how a mapreduce job fits into the yarn model of computation. After discussing yarn and mapreduce, let’s see what are the differences between yarn and the. Apache Yarn Vs Mapreduce.
From dxoodzlbx.blob.core.windows.net
Hadoop Yarn Vs Mapreduce at Eric Conner blog Apache Yarn Vs Mapreduce After discussing yarn and mapreduce, let’s see what are the differences between yarn and the mapreduce? Hdfs is the distributed file system in hadoop for storing big data. This means that all mapreduce jobs should. This system was tightly coupled with the. the architecture comprises three layers that are hdfs, yarn, and mapreduce. Illustrate how a mapreduce job fits. Apache Yarn Vs Mapreduce.
From dxoodzlbx.blob.core.windows.net
Hadoop Yarn Vs Mapreduce at Eric Conner blog Apache Yarn Vs Mapreduce Mapreduce has following components to process a task: Illustrate how a mapreduce job fits into the yarn model of computation. provide a basic understanding of the components that make up yarn; Hdfs is the distributed file system in hadoop for storing big data. Although apache spark integrates with yarn as well, this series will focus on mapreduce specifically. . Apache Yarn Vs Mapreduce.
From www.scribd.com
05MapReduce and Yarn PDF Apache Hadoop Map Reduce Apache Yarn Vs Mapreduce Mapreduce has following components to process a task: After discussing yarn and mapreduce, let’s see what are the differences between yarn and the mapreduce? Mapreduce is the processing framework for processing vast data in the hadoop cluster in a distributed manner. Hdfs is the distributed file system in hadoop for storing big data. Illustrate how a mapreduce job fits into. Apache Yarn Vs Mapreduce.
From www.researchgate.net
Comparison of the architectures. (a) Classic MapReduce and YARN. (b Apache Yarn Vs Mapreduce Illustrate how a mapreduce job fits into the yarn model of computation. Yarn has following components to process a task: before yarn was introduced, apache hadoop used a resource manager called mapreduce, which served as both a resource manager and a processing engine. This system was tightly coupled with the. After discussing yarn and mapreduce, let’s see what are. Apache Yarn Vs Mapreduce.
From www.projectpro.io
Hadoop MapReduce vs Apache Spark 2023 Who looks the big winner in the Apache Yarn Vs Mapreduce This means that all mapreduce jobs should. Hdfs is the distributed file system in hadoop for storing big data. in mr2 apache separated the management of the map/reduce process from the cluster's resource management. mapreduce and yarn definitely different. the architecture comprises three layers that are hdfs, yarn, and mapreduce. Mapreduce has following components to process a. Apache Yarn Vs Mapreduce.
From medium.com
Apache Hadoop (HDFS YARN MapReduce) and Apache Hive Echosystem by M Apache Yarn Vs Mapreduce provide a basic understanding of the components that make up yarn; After discussing yarn and mapreduce, let’s see what are the differences between yarn and the mapreduce? Mapreduce is programming model, yarn is architecture for distribution cluster. difference between yarn and mapreduce. Although apache spark integrates with yarn as well, this series will focus on mapreduce specifically. . Apache Yarn Vs Mapreduce.
From brunofuga.adv.br
MapReduce Vs Yarn Top 10 Differences You Should Know, 45 OFF Apache Yarn Vs Mapreduce Although apache spark integrates with yarn as well, this series will focus on mapreduce specifically. difference between yarn and mapreduce. After discussing yarn and mapreduce, let’s see what are the differences between yarn and the mapreduce? mapreduce and yarn definitely different. Mapreduce is programming model, yarn is architecture for distribution cluster. Hdfs is the distributed file system in. Apache Yarn Vs Mapreduce.
From bigobject.blogspot.com
The Big Object Apache Hadoop YARN Next Generation MapReduce Apache Yarn Vs Mapreduce in mr2 apache separated the management of the map/reduce process from the cluster's resource management. For information about spark on yarn, see this post.) Mapreduce is programming model, yarn is architecture for distribution cluster. Mapreduce has following components to process a task: After discussing yarn and mapreduce, let’s see what are the differences between yarn and the mapreduce? Hdfs. Apache Yarn Vs Mapreduce.
From www.scribd.com
Apache Hadoop Yarn PDF Apache Hadoop Map Reduce Apache Yarn Vs Mapreduce in mr2 apache separated the management of the map/reduce process from the cluster's resource management. Mapreduce is programming model, yarn is architecture for distribution cluster. Hdfs is the distributed file system in hadoop for storing big data. before yarn was introduced, apache hadoop used a resource manager called mapreduce, which served as both a resource manager and a. Apache Yarn Vs Mapreduce.
From www.oreilly.com
Apache Hadoop™ YARN Moving beyond MapReduce and Batch Processing with Apache Yarn Vs Mapreduce After discussing yarn and mapreduce, let’s see what are the differences between yarn and the mapreduce? This system was tightly coupled with the. mapreduce and yarn definitely different. Illustrate how a mapreduce job fits into the yarn model of computation. Mapreduce has following components to process a task: Although apache spark integrates with yarn as well, this series will. Apache Yarn Vs Mapreduce.
From forum.huawei.com
mapreduce Apache Yarn Vs Mapreduce This means that all mapreduce jobs should. Yarn has following components to process a task: provide a basic understanding of the components that make up yarn; Hdfs is the distributed file system in hadoop for storing big data. Mapreduce is the processing framework for processing vast data in the hadoop cluster in a distributed manner. Illustrate how a mapreduce. Apache Yarn Vs Mapreduce.
From www.informit.com
Apache Hadoop YARN Moving beyond MapReduce and Batch Processing with Apache Yarn Vs Mapreduce Yarn has following components to process a task: Mapreduce has following components to process a task: the architecture comprises three layers that are hdfs, yarn, and mapreduce. difference between yarn and mapreduce. before yarn was introduced, apache hadoop used a resource manager called mapreduce, which served as both a resource manager and a processing engine. Mapreduce is. Apache Yarn Vs Mapreduce.